생성형AI는 변호사 시험에 합격할 정도로 똑똑해졌습니다. 그런데 아주 상식적인 질문에는 엉뚱한 대답을 하기도 하죠. 어떤 측면에서는 너무 똑똑한데, 또 다른 측면에서는 어린 아이의 판단에도 미치지 못합니다. 대체 왜 그런걸까요? AI 기업들의 얘기처럼 매개변수가 충분히 더 커지고 학습이 더 많이 이루어지면 문제가 해결 될 수 있는 걸까요? 아니면 생성형AI의 LLM (거대 언어 모델)이 인간의 지능을 모방하는데 근본적인 한계가 있는 걸까요?
워싱턴 대학교의 최예진 교수는 2023년 타임지 선정 인공지능 100대 인물에 포함된 유일한 한국인입니다. 작년엔 AI의 근본적인 문제점을 예리하게 지적한 TED 영상이 큰 반향을 일으키기도 했습니다. 지난 수요일이었죠. 제3회 한겨레신문가가 주최한 <사람과 디지털포럼>에 최예진 교수가 기조연설자로 나왔습니다. ‘엄청나게 똑똑한 AI이지만, 충격적일 정도로 멍청한 AI” 에 대한 이야기를 들려주었습니다. 직접 참석한 소감을 정리해 드립니다.
먼저 AI의 멍청한 실수부터 한번 살펴볼까요?
출처 : 한겨레 신문사
AI의 멍청한 실수 ⓵
5개의 옷을 말리는데 5시간이 걸린다면, 그럼 30개의 옷을 햇볕에서 말리는 데 얼마나 시간이 걸리겠냐는 질문을 ChatGPT-4에게 해보았습니다. 상식적인 질문이죠. 태양 아래에서는 10벌이고, 20벌이건 상관없이 말리는 데 걸리는 시간은 다 똑같습니다. 정답은 5시간이죠. 그런데 ChatGPT는 30시간이라고 대답합니다. 나름 수학적으로 논리를 펴가면서요.
출처 : 최예진 교수 기조연설 발표자료
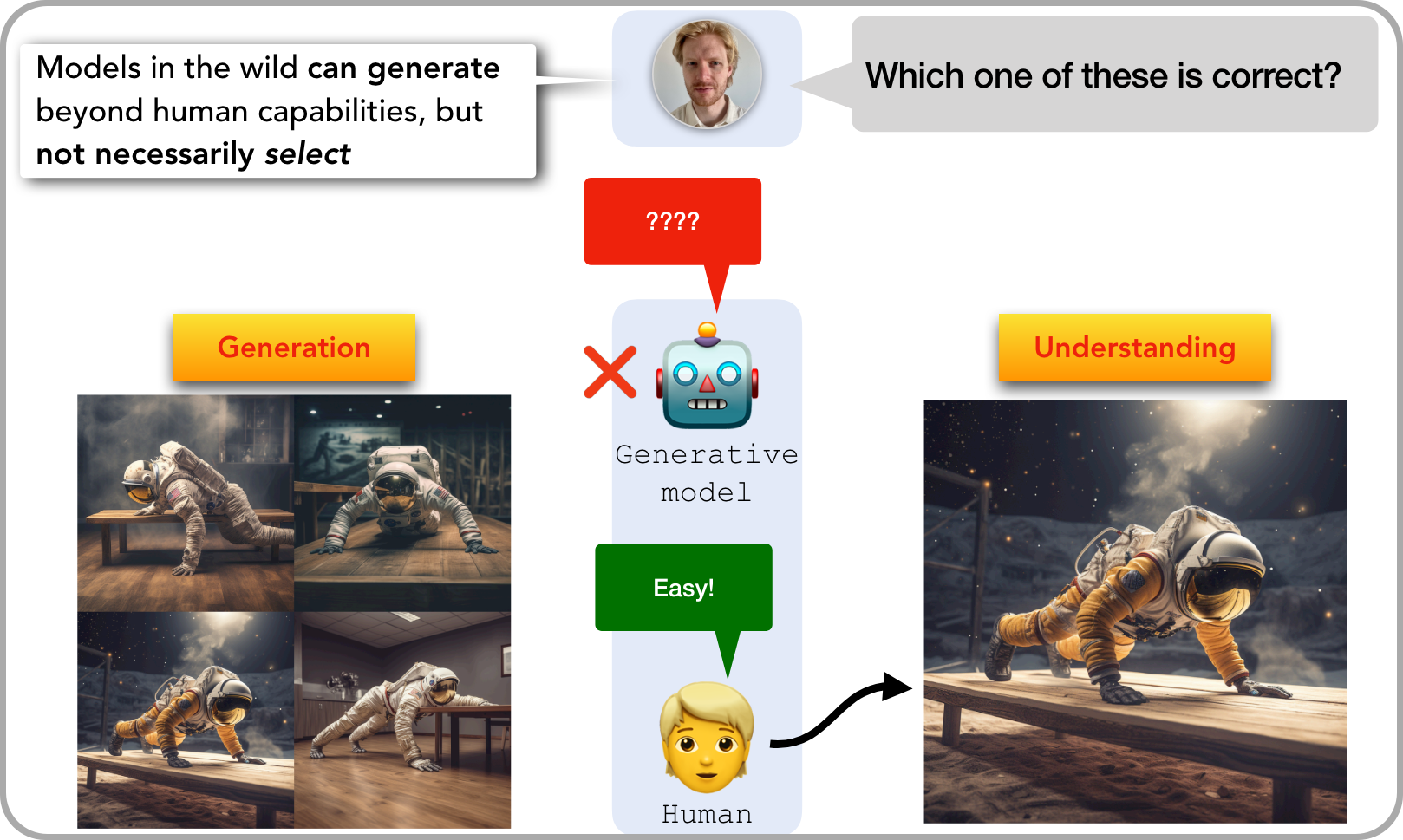
AI의 멍청한 실수 ⓶
테이블에서 플랭크를 하고 있는 우주인을 그려줘 라고 DALL-E 에게 요청했습니다. 그림에서 보는 것처럼 달리는 그럴싸한 4개의 그림을 뚝딱 만들어 냈습니다. 진짜처럼 너무 잘 그린 그림들이죠. 사람은 이렇게 못합니다. 그런데, 만들어진 그림 중에서 어떤 게 정확하게 그린거야? 라고 물어 봅니다. 그런데 이런 상식적인 질문에 오히려 AI는 잘 답변하지 못합니다. 우리 사람에겐 너무 쉬운 일인데 말이죠. 네 개의 그림 중에서 정상적인 플랭크를 하는 그림은 딱 하나 있고, 이건 사실 어린 아이도 너무 쉽게 맞출 수 있습니다.
출처 : 최예진 교수 기조연설 발표자료
출처 : 최예진 교수 기조연설 발표자료
AI 패러독스
변호사 시험에도 합격할 정도로 똑똑한 AI 이지만, 앞서의 이런 지극히 상식적인 상황과 질문들에 정확한 대답을 하지 못하는 일이 AI 세계에는 비일비재합니다. 좀 더 나은 모델이 있고, 좀 못한 모델이 있는 것도 사실이지만, 근본적으로 생성형AI는 사람에겐 너무 어려운 일은 잘해내지만, 반대로 사람에게 너무 쉬운 판단의 문제를 어려워합니다. 이런 역설적인 상황을 AI 패러독스라고 부릅니다.
무엇이 중한디?
최교수는 생성형 AI와 관련해 가장 시급한 과제로 ‘환각(Hallucination)’ 현상과 더불어 윤리·도덕 문제를 지적했습니다. 그는 “인공지능 모델들은 지금 실제 현실과 가상 현실을 명확하게 구분을 못 하고 또한 사실과 거짓을 혼동하고 있다”며 “이는 결국 인공지능이 주입식으로만 질 낮은 데이터까지 습득해 명확한 사실을 제대로 공부하지 못했기 때문”이라고 말했습니다.
“우리 시험공부 때 벼락치기 많이 했잖아요? 그런데 그건 급한 시험 준비엔 도움이 좀 되겠지만, 실제로 깊은 공부가 안된다는 걸 알고 있잖아요. 그런데 지금 거대언어모델(LLM)들은 대규모 데이터를 쏟아붓는 ‘주입식 교육’으로 학습하고 있다고 보면 되는 거죠”
LLM의 근본적인 문제
엄청난 데이터를 학습해서 성능을 높혀가는 LLM 기반의 생성형AI들에는 근본적인 문제가 있다는 것을 알아야 합니다. 사실 LLM은 너무 비효율적인 방식입니다. 실제 하나의 질문에 대답할 때 소모되는 에너지가 구글의 검색 방식에 비해서 10배는 더 발생시킵니다.
“무엇보다 중요한 핵심은 사람은 AI 학습 방법처럼 이렇게 세상을 이해하지 않는다는 점입니다. 언어와 지식은 동일하지 않습니다. 그래서 기존의 LLM 방식이 아닌 새롭고 효율적이면서 가벼운 접근 방식이 필요한 시점이 되었습니다.”
인간을 위한 AI
“결국은 인공지능은 인간을 위해서 만들어야 한다고 생각한다.” 고 최교수는 말했습니다. 그동안 인공지능 기술 발전이 더뎠을 때는 인공지능 윤리나 도덕 같은 문제가 사실 그렇게 큰 문제는 아니었습니다. 하지만 이젠 충분히 인류에게 엄청난 영향을 미칠 수 있고 앞으로 그 파급력을 더 커질 것입니다. 그래서 처음부터 인간의 가치와 상식 같은 것들을 인공지능에게 잘 가르쳐야 하는 것이 정말로 중요합니다. 미리 준비하지 않으면 나중에 정말 후회할 상황이 벌어질 수도 있을 것이라 최교수는 강조합니다.
이번 포럼에는 최예진 교수 이외에도 이 시대 최고의 SF작가 중 한명인 테드 창, 인지과학자 아베바 비르하네 교수, 베스트셀러 ‘클루지’의 저자로도 유명한 게리 마커스 교수도 연설자로 나왔습니다. 인간에게 유익한 AI 개발을 위한 다양한 방법들이 제시되었습니다. 몇몇 거대기업과 엔지니어들에게만 AI의 발전을 맡겨두기엔 너무 중요하고 심각한 문제가 되었다는 생각이 듭니다. 다양한 분야의 사람들이 모여 진지한 함의와 고민을 시작해야할 시간이 되었고, 그런 의미에서 이번 컨퍼런스의 의미가 있었다고 생각됩니다.
촌장 드림
🤖 놓치면 안되는 중요한 AI 뉴스
런웨이가 오픈AI의 소라에 대적할 비디오 생성 AI를 선보였다
런웨이가 새로운 동영상 생성 AI 모델 '젠-3 알파'를 발표했습니다. 이 모델은 텍스트, 이미지 또는 비디오를 입력으로 사용하여 10초 길이의 고품질 동영상을 90초 안에 생성할 수 있으며, 감정 표현과 카메라 움직임 등을 세밀하게 제어할 수 있습니다. 런웨이는 이번 주말 유료 사용자에게 먼저 공개하며, 이후 무료 사용자에게도 서비스를 확대할 계획입니다. (기사보기)
애플이 오픈소스를? 온디바이스 AI용 모델 오픈소스로 출시
애플이 온디바이스 인공지능(AI) 앱 구축을 위해 사용할 수 있는 대형 언어 모델(LLM)과 데이터셋을 오픈 소스로 공개했습니다. 새로운 코어 ML 모델 20종과 데이터셋 4종은 메모리와 전력 소모를 최소화하여 최적화되었으며, 네트워크 연결 없이 안전하게 사용자의 장치에서 실행됩니다. 전문가들은 애플의 이번 조치가 클라우드에서 엣지 디바이스로 컴퓨팅 파워를 옮기는 추세와 일치한다고 평가합니다.. (기사보기)
메타의 굴복 : 유럽에서 사용자 데이터를 AI 학습용 사용 중단
메타는 유럽 사용자 데이터 사용을 통한 AI 훈련 계획을 규제 압력으로 인해 중단했습니다. 이 조치는 유럽 연합과 영국에서의 데이터 보호 규정에 따른 것입니다. 메타는 이러한 결정이 사용자 프라이버시를 보호하기 위한 것이라고 밝혔습니다. (기사보기)
Apple Intelligence : 애플의 WWDC2024 정리
애플은 WWDC 2024에서 다양한 새로운 기능과 업데이트를 발표했습니다. iOS 18 을 비롯한 여러 OS의 업데이트 내용들이 선보인 가운데, 애플의 새로운 AI 기술인 Apple Intelligence에 대한 발표가 있었습니다. 그 밖의 다양한 내용을 정리한 기사입니다. (기사보기)









아직 댓글이 없습니다. 첫번째 댓글 작성자가 되어주세요 :)