[프레임워크, 쿼리] 저장시스템을 최적화하기 위해 무엇을 하고 있는가?
저장 시스템에서의 최적화는 다음과 같이 시간복잡도 측면과 공간복잡도 측면으로 나누어서 살펴보고자 한다.
먼저 시간복잡도 측면에서의 데이터 입력 속도와 출력 속도를 줄이기 위한 방안으로 데이터 Buffered IO 기법, 높은 데이터 응집성 구조, 캐싱 기법 등을 사용한다.
Buffered IO의 경우 입력 속도를 높이기 위해 사용되며, Memory에 Partition 단위로 데이터를 모았다가 File에 저장하는 구조이다.
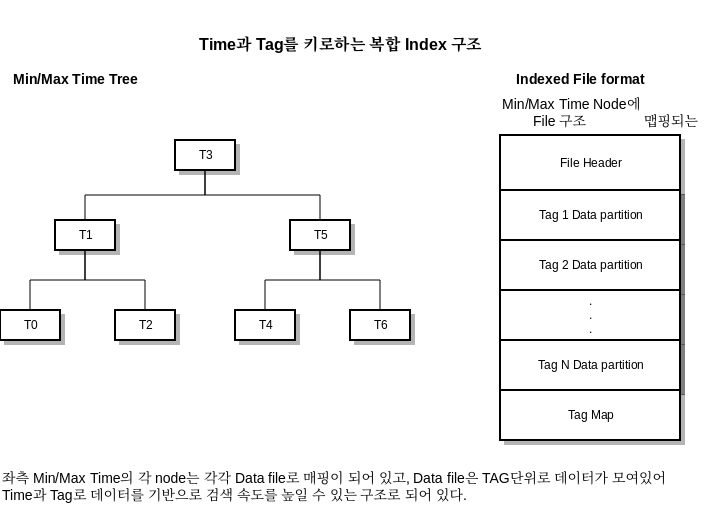
데이터의 조회 속도를 높이기 위한 데이터의 응집성을 높여 조회 시 필요한 데이터 위조로 load 하며, 이를 위해 Time과 Tag를 키로 하는 복합 Index 구조를 적용하였다.
또한, 사용자가 자주 조회하는 데이터의 경우 요청 시 조회 빈도수가 높은 데이터가 Memory에 캐싱되어 가장 병목이 심한 Disk IO 과정을 생략함으로써 응답 속도를 높일 수 있다.
다음으로 공간복잡도 측면의 최적화를 위해 일반적으로 사용되는 방법은 데이터를 File에 저장할 때 디스크 사용량을 줄이기 위해 데이터를 압축해서 저장하는 방식이다.
모든 데이터를 type과 무관하게 row 단위로 일괄적으로 압축 저장할 경우 압축 효율이 떨어질 뿐만 아니라, 데이터를 load 할때 의도하지 않은 컬럼의 데이터까지 모두 load하게 되어 불필요한 IO가 발생하게 된다.
데이터를 컬럼방식으로 저장함으로써 이런 문제들을 개선할 수 있다.
먼저 데이터 type 별 최적화된 압축 알고리즘을 사용함으로써 전반적인 압축 효율을 높일 수 있으며 데이터 조회 시 필요한 컬럼들만 memory에 load 함에 따라 Disk IO를 최소화 할 수 있고, 결과적으로 memory 사용량도 줄일 수 있다.
DB에 대한 스트레스(작업부하)가 일어났을 때 부하를 어떻게 해소하는가?
Query 실행 시 explain 키워드를 이용하여 Query 수행에 따른 자원 사용량 및 시간을 알 수 있다. Explain 결과를 분석하여 병목 구간을 알아내고 개선 방안을 마련한다.
개선 방안으로는 먼저 query를 tuning 하는 방안, 두번째로 DB 설정을 tuning 하는 방안, 셋째 OS 설정을 tuning 하는 방안, 넷째 HW 자원을 증설하는 방안, 끝으로 DBMS software 자체를 개선하는 방안을 들 수 있다.
분야별 적합한 DB는 무엇인가?
- 환율, KOSPI 예측이 필요한 금융 경제
- 금융 분야는 미시적인 관점과 거시적인 관점에서 모두 접근해야 한다.
금융 분야는 정보가 실시간으로 쏟아져 나오는 분야로 미시적인 관점에서는 데이터를 빠르게 분석하는게 중요하고, 다라서 높은 성은이 보장되는 Memory DB를 사용하는게 유리하다.
반면, 거시적인 관점에서 장기적인 추이를 보고 분석하는 부분은 디으크와 같은 비휘발성 저장소에 대량의 데이터를 제한된 시간 안에 저장해야 하기 때문에 SQL on Hadoop과 같은 빅데이터 솔루션을 사용해야 한다.
- 상관관계 분석이 필요한 환경, 정부, 복지
- 데이터 간 관계가 중요하여, 관계형 DBMS를 사용하는게 유리했지만 최근에는 데이터의 상관관계 분석에 있어서도 데이터의 양이 많아져 데이터 간 관계를 조회하는데 유리한 관계형 DBMS와 대량의 데이터를 효율적으로 저장하고 summary 하는데 유리한 컬럼 기반 DBMS를 동시에 사용하는 경우가 늘어났다.
관계형 DBMS에는 데이터의 양이 많지는 않지만 데이터 조회 시 확인이 필요한 부가정보를 저장하고 대량으로 발생하는 컬럼 기반 DBMS에 저장하여 하이브리드 형태로 사용하는 것이 유리하다.
- 대용량 비정형 데이터를 관리해야 하는 SNS 기업
- Social Network Service(SNS) 기업은 객체(사용자) 간의 자유로운 의사소통과 정보 공유, 그리고 인맥 확대 등을 통해 사회적 관계를 생성하고 강화해주는 온라인 플랫폼을 의미한다.
그래프 이론은 데이터를 노드와 에지(Edge) 관계로 표현하는 수학 이론이다. SNS와 그래프 이론을 접목시켜 설명하면 객체(사용자)를 노드로 지정하고, 객체 간 관계를 에지로 연결할 수 있기 때문에 사회적 관계 표현에 있어 최적화된 구조를 가지고 있다.
- 시간의 흐름에 따라 데이터를 확인해야하는 제조업
- 제조업 분야에서는 시계열DB의 사용이 매우 유리한 분야이다. 공정 자동화와 함께 공장에서 솓아져 나오는 데이터는 갈수록 늘어나고 있으며, 이러한 데이터는 실시간 조회/분석과 함께 장기적인 관점에서 추이를 보고 분석하는 시간대에 따른 비교/분석이 필요한 분야이다.
기존의 RDBMS, Hadoop, NoSQL, RTDB등과 같은 DB는 설계 개념상 시스템 구축 시 많은 HW 자원을 필요로 해 높은 비용이 발생하게 된다.
반면, 시계열DB는 이러한 환경에 적합하게 설계된 DB로 상대적으로 적은 HW 자원으로 기존 DB보다 더 높은 성능을 보일 수 있고, 결과적으로 낮은 비용으로 안정적인 성능을 가진 시스템을 구축할 수 있다.
자세한 내용은 아래 URL을 통해 확인 부탁드립니다.

아직 댓글이 없습니다. 첫번째 댓글 작성자가 되어주세요 :)